107180通过匹配训练轨迹进行数据集蒸馏0George Cazenavette 1 Tongzhou Wang 2 Antonio Torralba 2 Alexei A. Efros 3 Jun-Yan Zhu 101 卡内基梅隆大学 2 麻省理工学院 3 加州大学伯克利分校0...
”数据集蒸馏 CIFAR-100 ImageNet 蒸馏图像“ 的搜索结果

我们在CIFAR-100和ImageNet(ILSVRC 2012)图像分类数据集中广泛评估了我们的方法,并显示了最新的性能。 代码 先决条件: Matlab 2017b。 VlFeat(0.9.20)。 MatConvNet(1.0-beta25)。 ResNet-Matconvnet。 所有...
106661.00.90.80.70.60204060801 0204060800.5100时代时代CFD一Bt -RePrt -标准特斯特斯E- RePr- 标准列车火车00RePr:卷积滤波器Aaditya PrakashBrandeis大学[email protected]詹姆斯·斯托勒·布兰代斯大学...
CSDN翻译链接 kaggle英文链接对这篇采访的总结如下: 日本学者 Kunihiko Fukushima 提出的神经认知机(NeoCognitron)对CNN的发展有着启迪性的意义,其提到模式识别机制的自组织神经网络模型不受位置变化的影响。...

PaddleClas 融合已有的知识蒸馏方法 [2,3],提供了一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation),基于 ImageNet1k 分类数据集,在 ResNet_vd 以及 MobileNet 系列上的精度均...






目前的蒸馏方法主要基于从中间层蒸馏深层特征,而logit蒸馏的意义被大大忽视。为了为研究logit蒸馏提供一个新的观点,我们将经典的KD损失重新表述为两部分,即目标类知识蒸馏(TCKD)和非目标类知识蒸馏(NCKD)。...



机器之心 & ArXiv Weekly Radiostation参与:杜伟、楚航、罗若天本周的重要论文是CVPR 2020 公布的各奖项获奖论文,包括最佳论文和最佳学生论文等。目录:Knowledge Distillation: A SurveyDescription Based ...

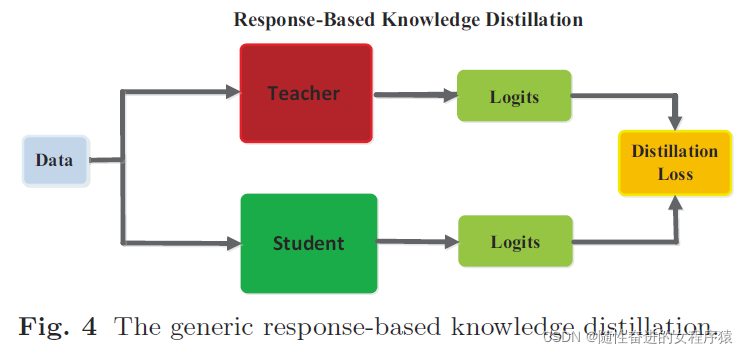
知识提取(KD)是一种有效的学习范式,通过利用从教师网络中提取的额外监督知识来提高轻量级学生网络的性能。大多数开创性研究要么只从一位老师那里学习提炼学习方法,忽视了学生可以同时从多位老师那里学习的潜力,...
120520DearKD:用于视觉transformer的数据高效早期知识蒸馏0Xianing Chen 1* , Qiong Cao 2† , Yujie Zhong 3 , Jing Zhang 4 , Shenghua Gao 156† , Dacheng Tao 2401 上海科技大学,2 ...
目前,模型蒸馏技术已经广泛应用于图像分类、目标检测、文本识别、机器翻译等多个领域。KL散度(Kullback Leibler Divergence):又称KL散度,两个分布之间的距离,用来衡量两个概率分布之间的差异。KL散度的值越小...




点击上方,选择星标或置顶,每天给你送干货!作者 |傅斯年Walton地址 |https://zhuanlan.zhihu.com/p/160206075编辑 |机器学习算法与自然语...


推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地